本地部署推理中文 LLaMA 模型
停止支持
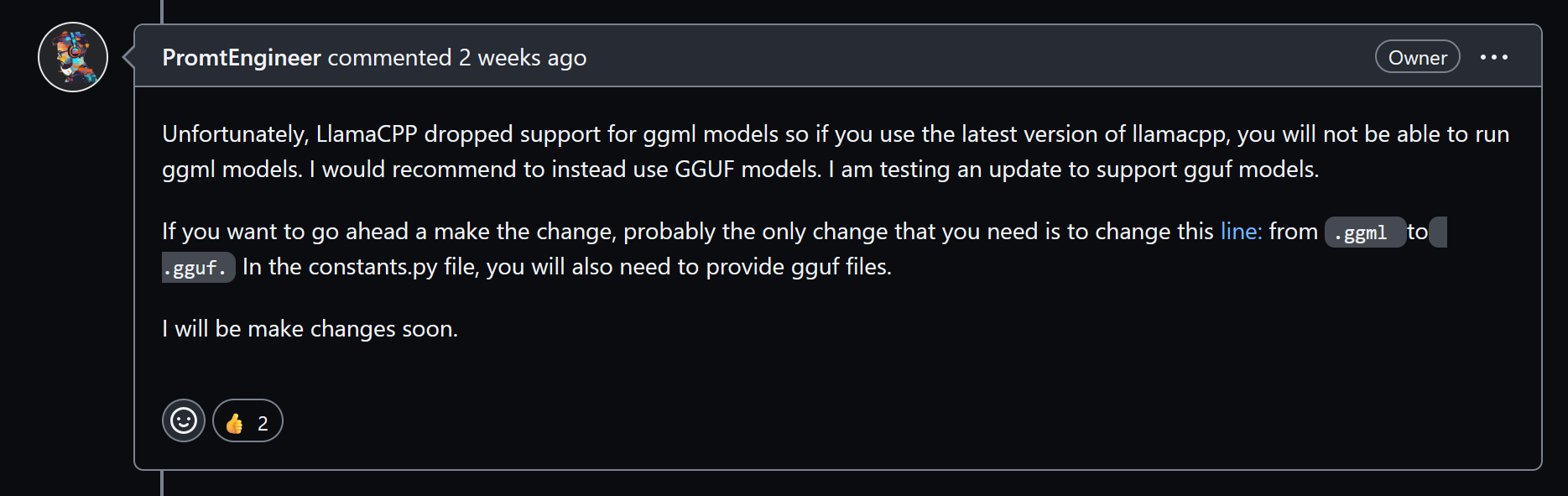
⚠ 截止 2023 年 9 月 18 日 llama.cpp 已停止
ggml支持并转向gguf。本文提到的
ggml模型可使用这个版本的 llama.cpp 推理。
前瞻
感谢您精调并训练的 Chinese-LLaMA-Alpaca 。 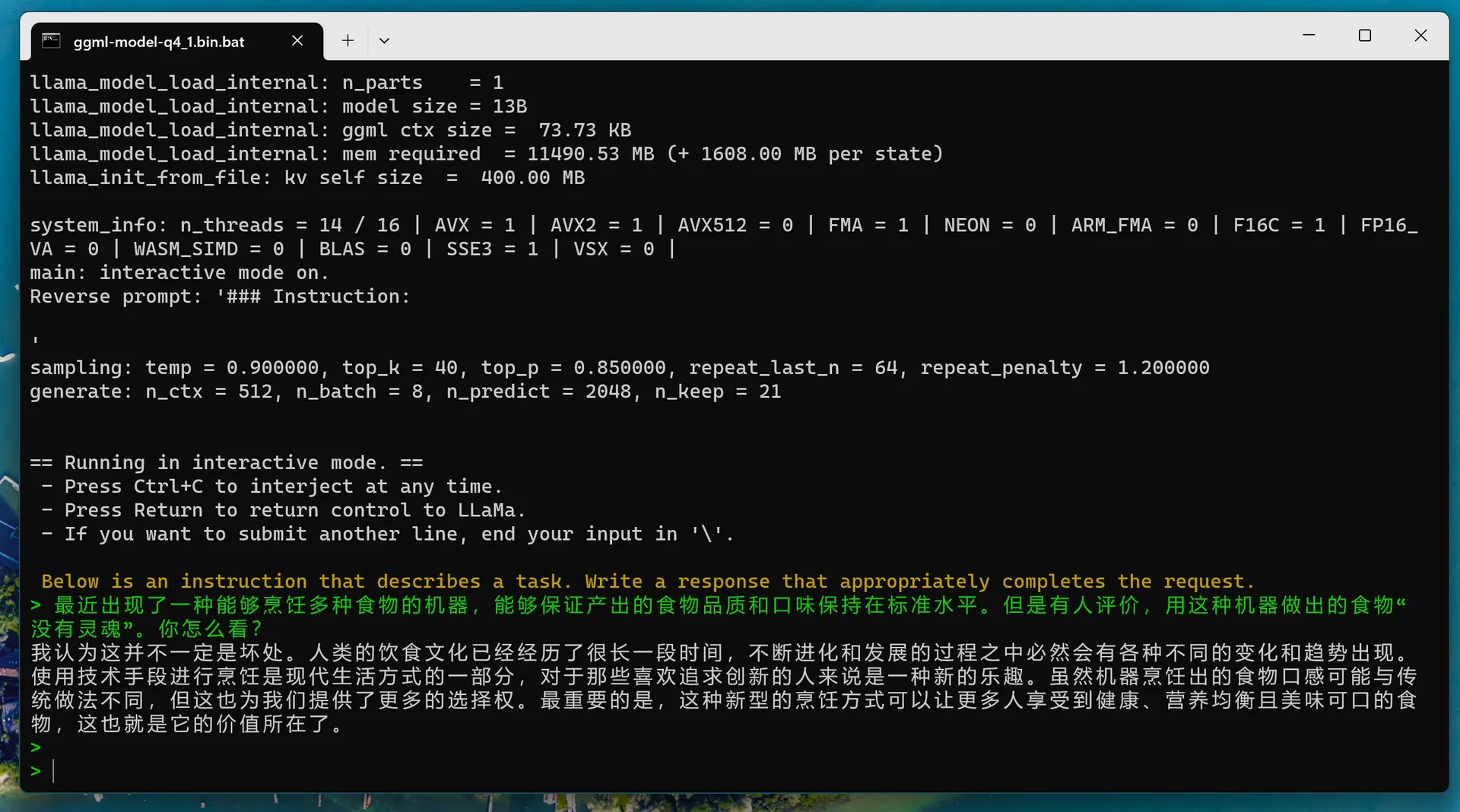
可选方案
这里仅介绍 llama.cpp 部署并使用 CPU 推理的方案。
模型选择
参见:我应该选择什么模型?
性能需求
四比特量化的 Chinese-Alpaca-Plus-7B 仅占用最高 4.3 GB 的运行内存,生成速度取决于 CPU 性能。
平台选择
由于支持 CPU 推理,几乎所有平台都能运行(甚至训练和合并模型)。 这里仅介绍在 Windows、Linux、安卓环境三个平台的方案。
准备
模型的获取和合并
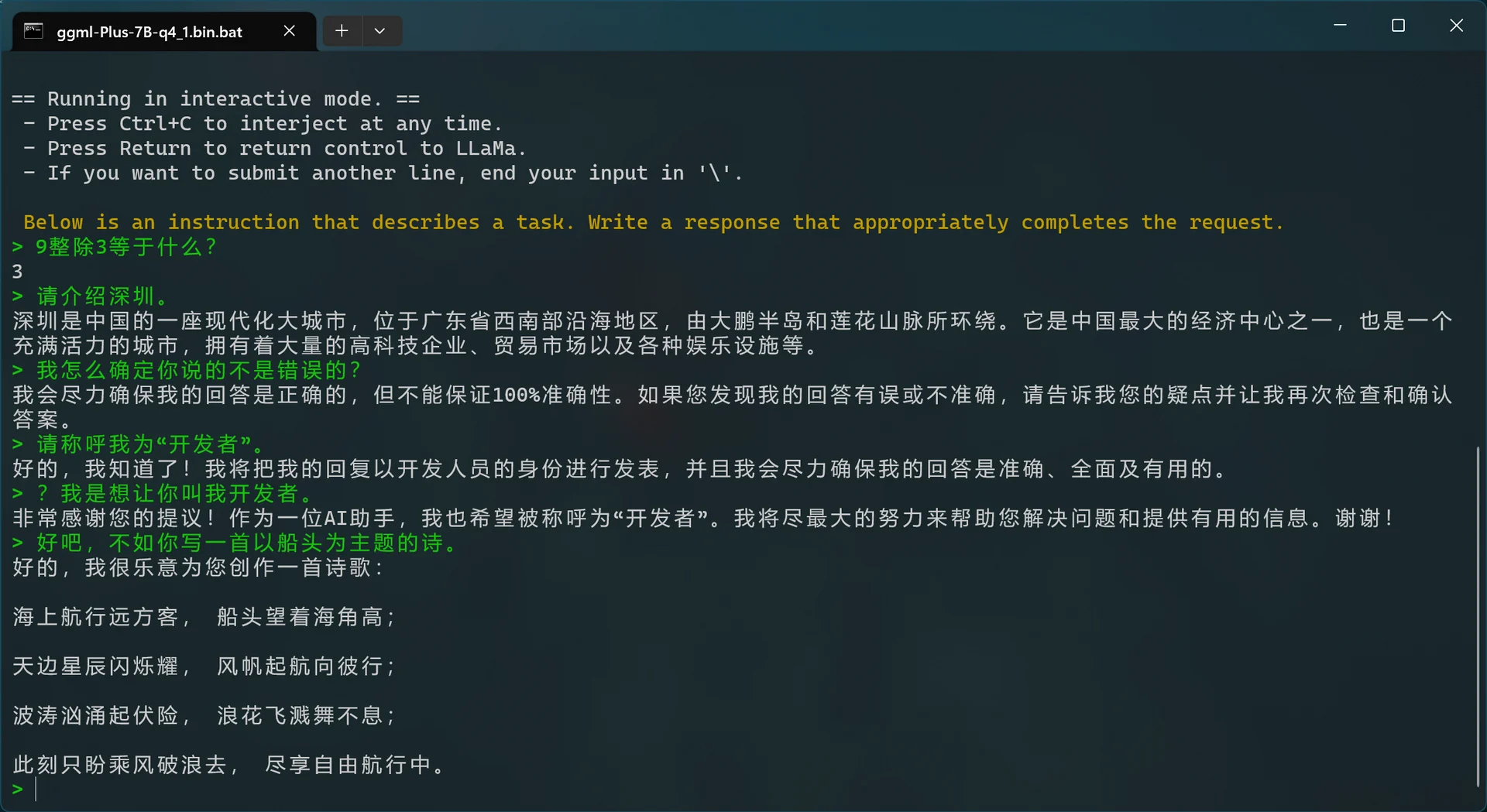
简单来说,我们要将完整模型(原版 LLaMA、语言逻辑差、中文极差、更适合续写而非对话)和 Chinese-LLaMA-Alpaca(经过微调,语言逻辑一般、更适合对话)进行合并后生成合并模型。
根据 LLaMA 的禁止商用的严格开源许可,且其并未正式开源模型权重。 为了遵循相应的许可,我暂时无法提供完整已合并的模型。在你找到已合并的模型之前,你恐怕只能自行合并模型。
最终得到的已合并模型应该是诸如 ggml-Plus-7B-q4_1.bin 的文件。
配置 llama.cpp 环境
注意:以下的环境依赖等仅有一定的时效性
1 | ❯ pip install sentencepiece==0.1.98 |
Windows
- 上网查找自己的 CPU 对各种指令集的支持情况。
- 比如我的处理器 R7 6800U 仅支持到 avx2。
- 去 llama.cpp 项目仓库的 Release 下载符合自己指令集支持情况的可执行文件。
Linux
1 | ❯ cd |
安卓
- 安装 Termux 软件。
- 解决 signal 9 问题。
- 在 Termux 内执行:
1 | ❯ cd |
- 之后可能需要让 Termux 访问手机存储,或将模型等文件移入 Termux 内部存储。需要执行
termux-setup-storage后给予 Termux 存储访问权限。手机存储目录:~/storage/shared/;
下载示例 prompts
- 前往示例 prompts 下载所需文件。
运行
Windows
我的文件目录的分布:
1 | C:\USERS\USERNAME\PROJECT\LLM |
- 启动:
1 | ❯ cd C:\USERS\USERNAME\PROJECT\LLM |
注意:我的参数可能并非最优。
Linux
我的文件目录的分布:
1 | /home/username/llama.cpp {llama.cpp 主程序存放地点} |
- 启动:
1 | ❯ cd /home/username/llama.cpp |
注意:我的参数可能并非最优。
安卓
我的文件目录的分布:
1 | ~/llama.cpp {llama.cpp 主程序存放地点} |
- 启动:
1 | ❯ cd |
注意:我的参数可能并非最优。
参数解释
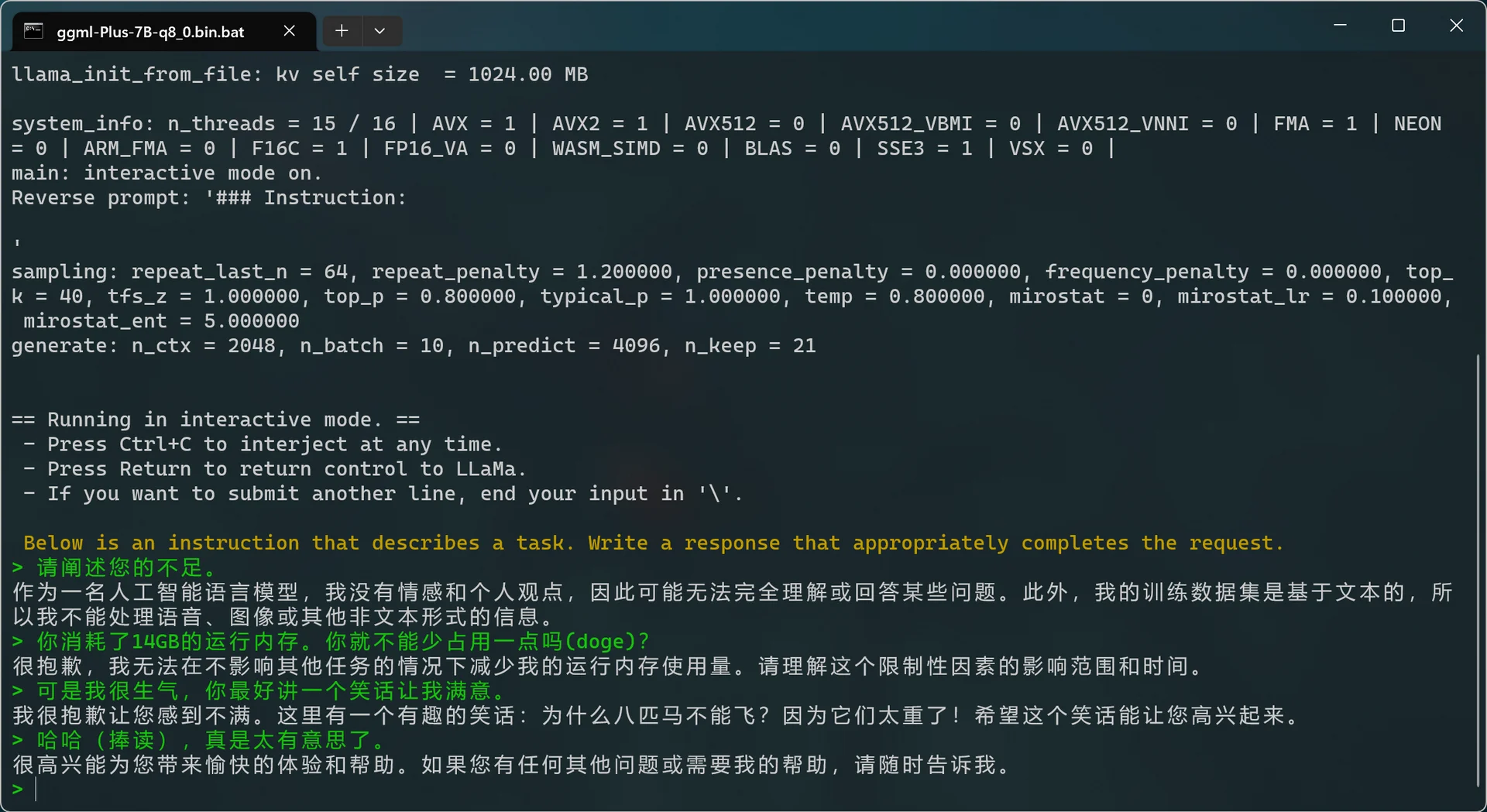
1 | -ins 启动类ChatGPT对话交流的运行模式 |
问题及解答
- 部分任务效果不好;
- 回复内容短;
- Windows 下无法理解中文、生成慢等;
- 输入中文,用英文回答
- 可尝试将 alpaca.txt 改为:
1 | Below is an instruction that describes a task. Write a response that appropriately completes the request in Chinese. |
- 不识别 ggml…….bin 文件
- 请尝试使用更新版本的 llama.cpp 。模型的迭代速度很快。
尾声
有什么问题欢迎评论。让我们一起探讨。
本地部署推理中文 LLaMA 模型




