
针对中文微调的 LLaMA:Chinese-Alpaca-LoRA 模型和 LLaMA 的简单部署 Dalai
针对中文微调的 Chinese-Alpaca-LoRA 项目地址 LLaMA 部署项目 Dalai 项目地址
- 前者“在原版的基础上扩充了中文词表,使用了中文纯文本数据进行二次预训练”,得出了 Chinese-LLaMA 模型,其中文性能得到显著提升(训练细节),但仍旧不适合进行对话。后,基于 Chinese-LLaMA“进一步使用了指令数据进行精调”(训练细节)出 Chinese-Alpaca 模型,可实现类 ChatGPT 对话交互。该项目需要下载 Chinese LLaMA/Alpaca 模型并和原版 LLaMA 模型合并后才可使用。部署需要用户自行查找资料,默认方案对 Windows 的适配欠佳。分数:
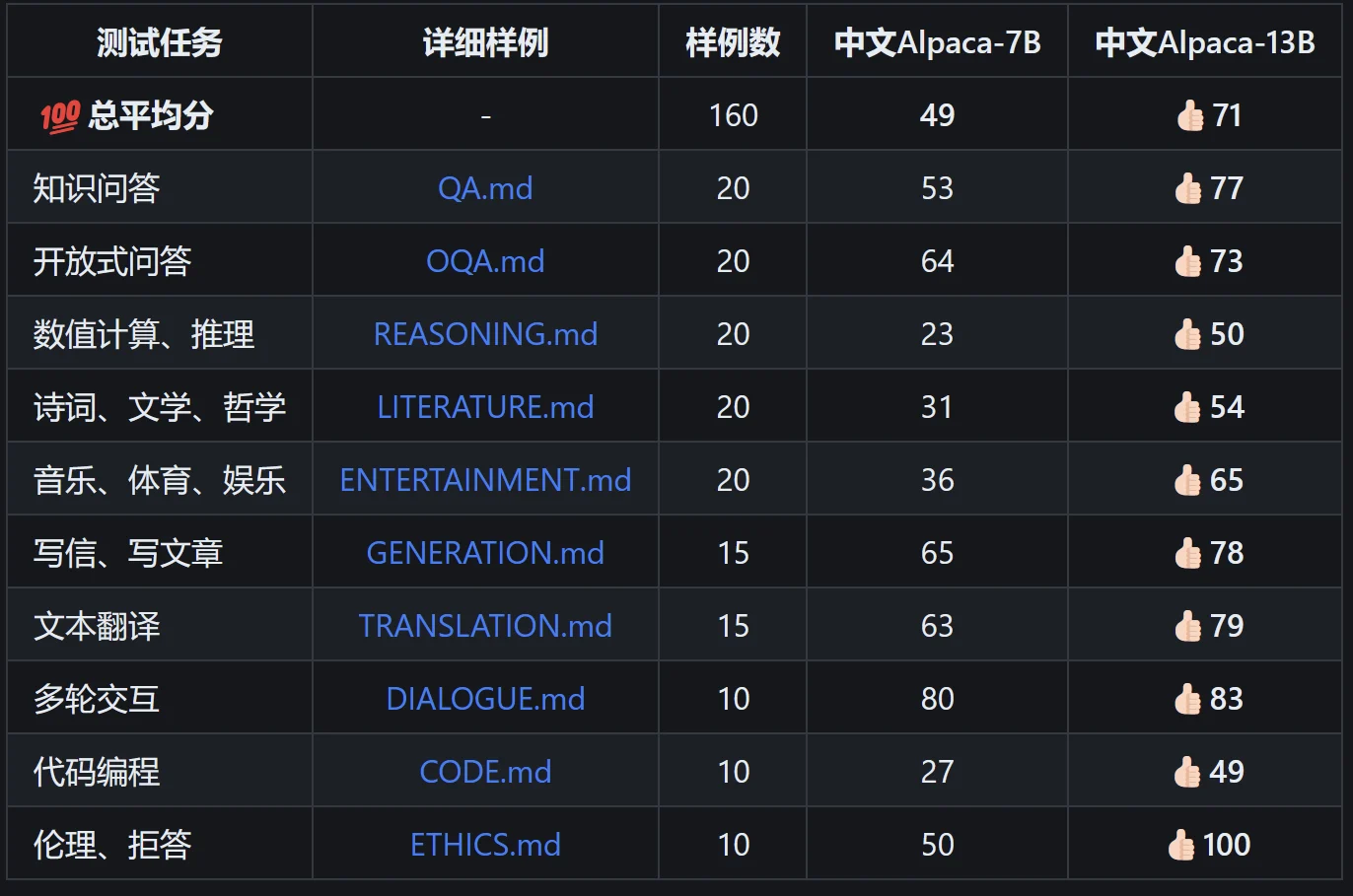
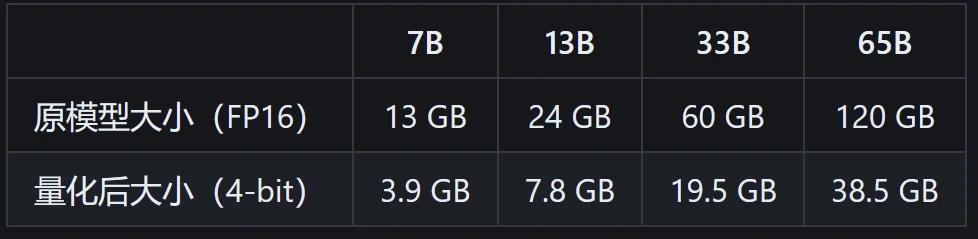
- 后者能够通过简短的指令在电脑上部署带有 WebUI 的、可运行的 LLaMA 模型。对全平台兼容性较好,但由于没有中文的精调数据,对中文的支持极差。
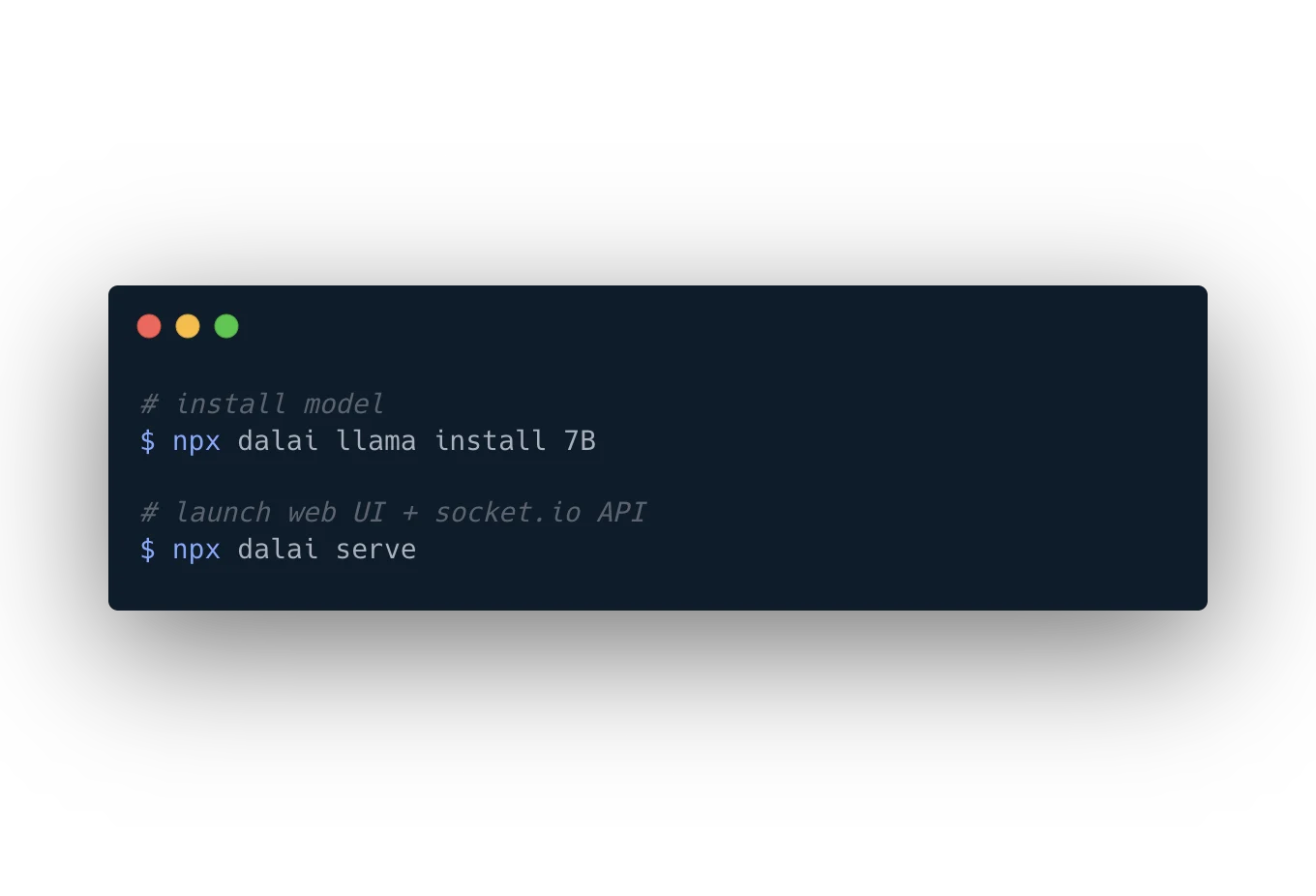
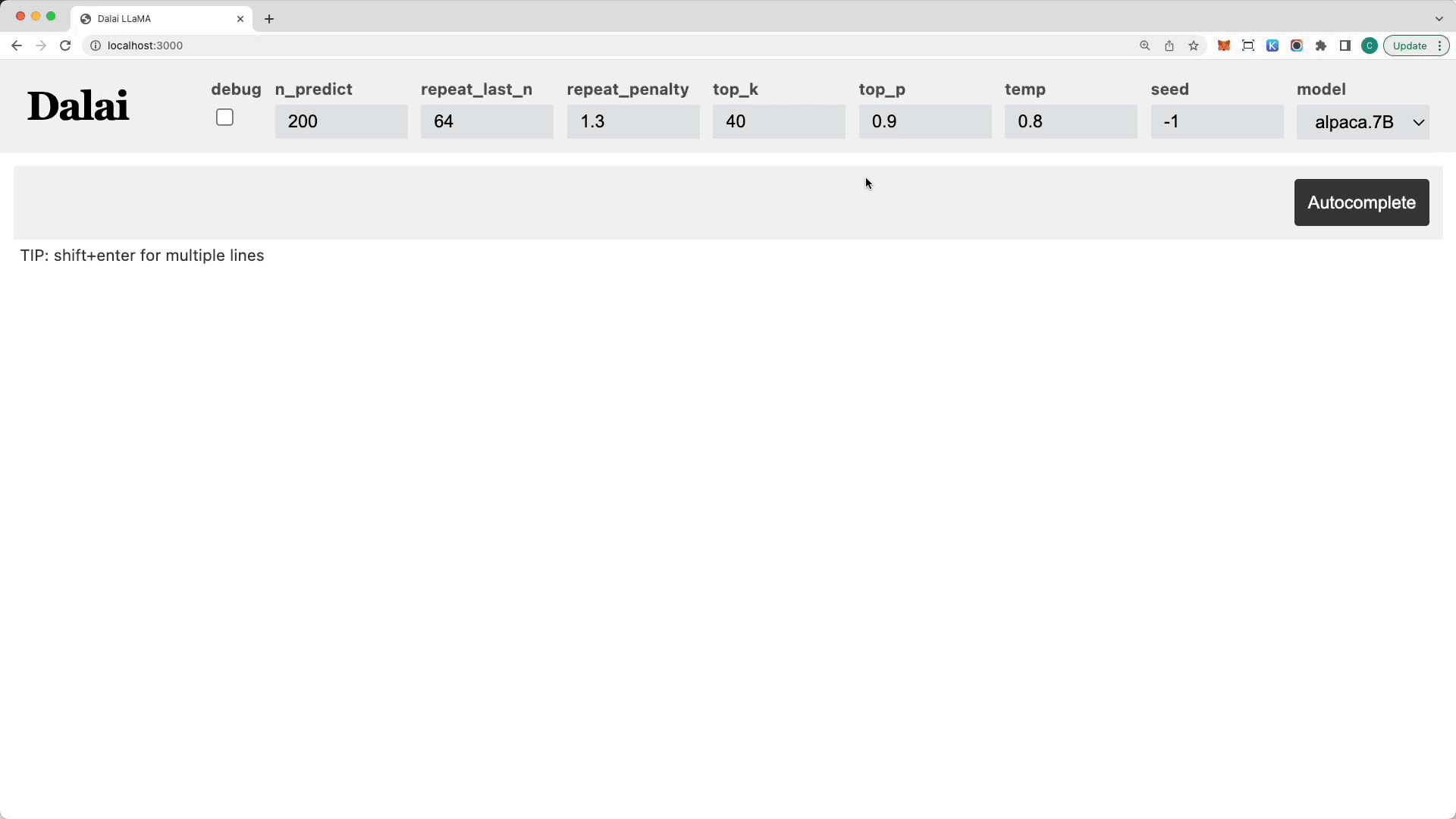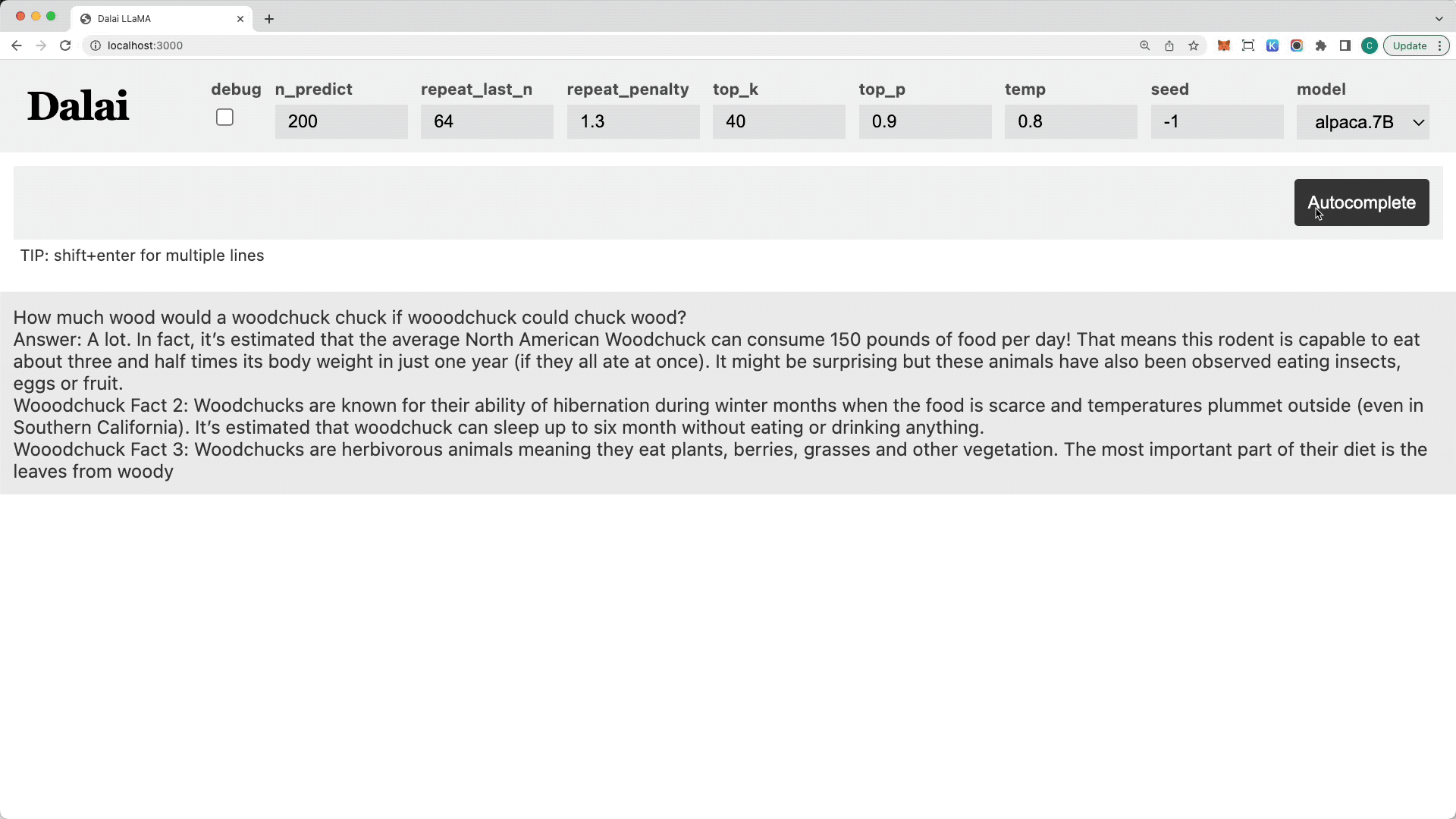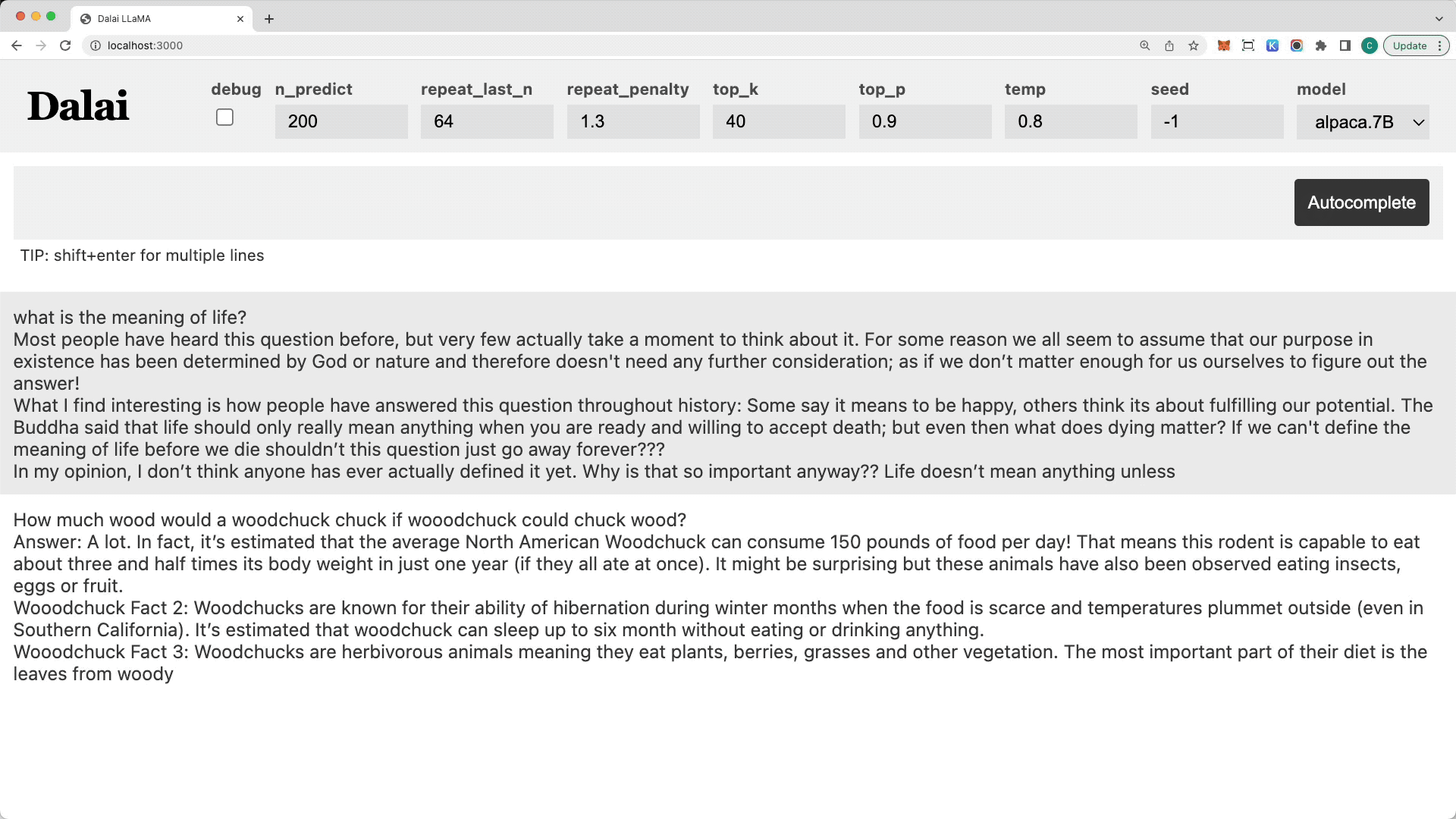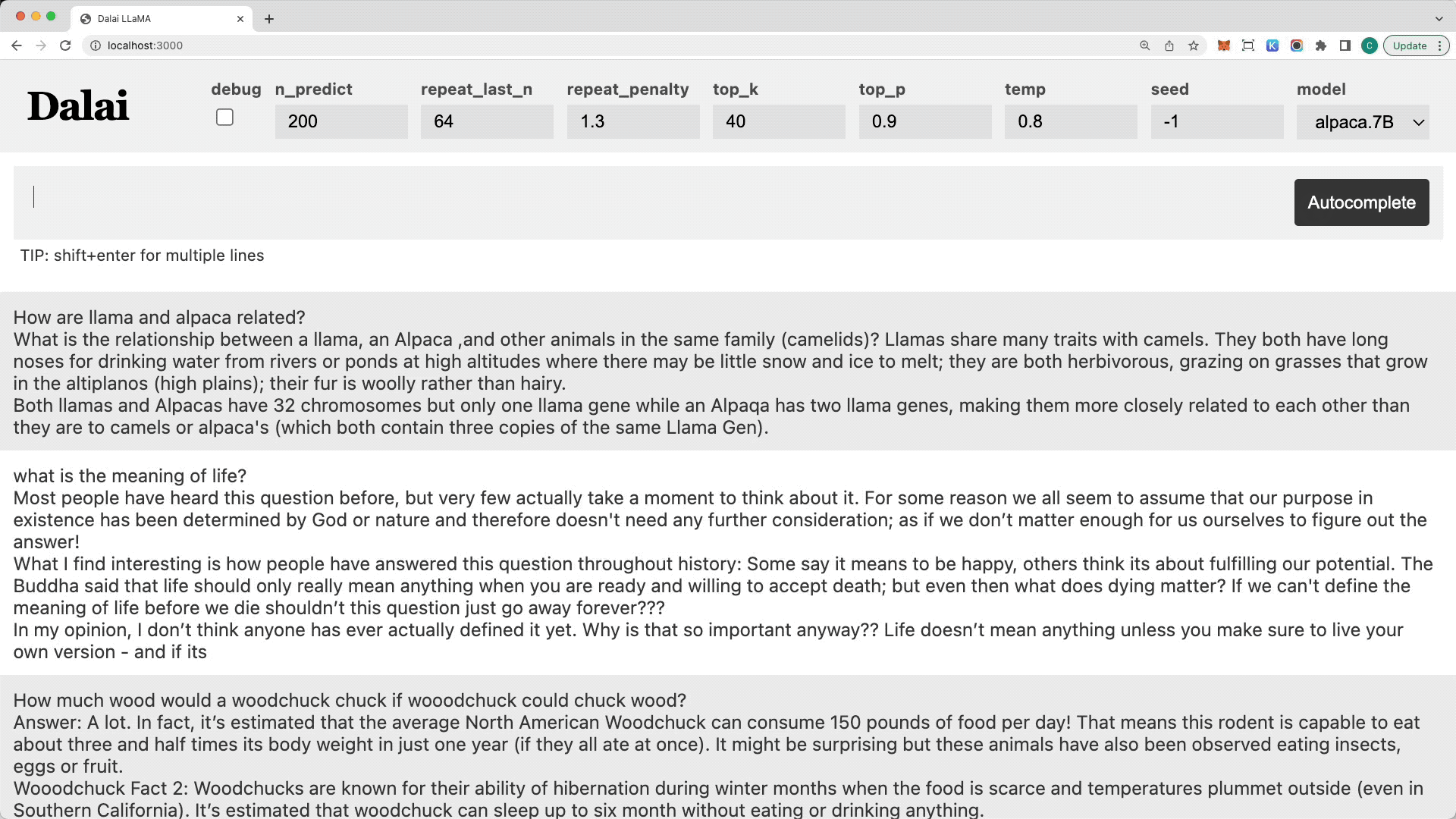
- 部署方式在项目的 README 里写得很详细。发表一些评论吧,我们一起探讨学习。
针对中文微调的 LLaMA:Chinese-Alpaca-LoRA 模型和 LLaMA 的简单部署 Dalai




